
[ 스택 (Stack) ]
: 삽입과 삭제 연산이 후입선출 (LIFO : Last-In First-Out) 로 이루어진 자료구조
* 우선탐색 (DFS:Depth First Search), 백트래킹 종류의 코딩에 효과적이다.
( 후입선출은 개념 자체가 재귀함수 알고리즘 원리와 일맥상통하기 때문이다. )
스택은 값을 넣는 곳과 빼는 곳이 일치한다. 새 값이 스택에 들어가면 top이 새 값을 가리킨다.
스택에서 값을 빼낼 때 pop은 top이 가리키는 값을 스택에서 빼게 되어있으므로 결과적으로는 가장 마지막에 넣었던 값이 나오게 된다.
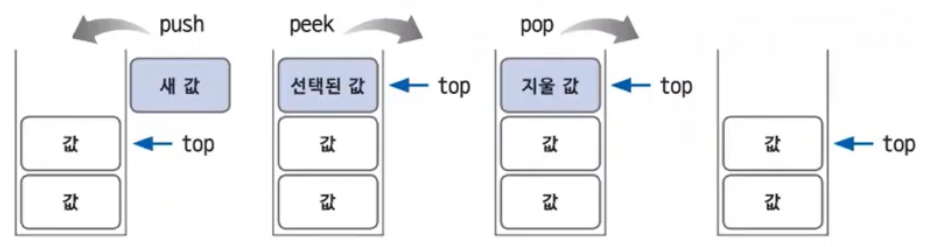
* 스택 관련 용어
1) top : 데이터의 삽입과 삭제가 발생하는 위치를 가리키는 용어
2) push : top 위치에 새로운 데이터를 삽입하는 연산
3) pop : top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산
4) peek : top 위치에 현재 있는 데이터를 단순하게 확인만 하는 연산
[ 큐 (Queue) ]
: 삽입과 삭제 연산이 선입선출 (FIFO : First-In First-Out) 로 이루어진 자료구조
스택과 다르게 먼저 들어간 데이터가 먼저 빠져나간다.
그래서 삽입과 삭제가 양방향에서 이루어진다.
아래의 그림을 보면 알 수 있는데 새로운 데이터 추가는 큐의 rear 부분에서 이루어지고,
삭제는 큐의 front 부분에서 이루어진다.
* 너비 우선 탐색 (BFS:Breadth First Search) 에서 자주 사용하므로 큐에 대해 잘 알아두어야 한다.)

* 큐 관련 용어
1) rear : 큐에서 가장 끝에 위치한 데이터를 가리키는 영역
2) front : 큐에서 가장 앞에 위치한 데이터를 가리키는 영역
3) add : rear 부분에 새로운 데이터를 삽입하는 연산
4) poll : front 부분에 있는 데이터를 꺼내서 확인하고 삭제하는 연산
5) peek : 큐의 맨 앞 (front) 부분에 있는 데이터를 확인할 때 사용하는 연산, 삭제 X
[ 우선순위 큐 (Priority Queue) ]
: 값이 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 나오는 자료구조
큐의 설정에 따라서 front 부분에 항상 최댓값 또는 최솟값이 위치하게 된다.
* 우선순위 큐는 일반적으로 힙(heap)을 이용해 구현하는데 힙은 트리 종류 중 하나이다.
'자료구조' 카테고리의 다른 글
| 선택 정렬(Selection Sort) (0) | 2023.01.31 |
|---|---|
| 버블 정렬 (Bubble Sort) (0) | 2023.01.22 |