
[ 그룹 쿼리와 집합 연산자 목차 ]
1. 기본 집계 함수
1) SUM
2) AVG
3) MAX, MIN
4) 그룹 함수와 단순 컬럼
5) COUNT
2. GROUP BY절
3. HAVING 조건
4. 집합 연산자
1) UNION
2) UNION ALL
3) INTERSECT
4) MINUS
5) 집합 연산자 제한사항
** 주기적으로 백업 받는 것 : Batch
통 틀어서 백업 받는 것 : Full Back up
증가분에 대한 백업 : Increamental
--> MINUS 집합 연산자를 활용한 방법,,?
[ 1 ] 기본 집계 함수
- 그룹 함수는 하나 이상의 행을 그룹으로 묶어 연산하여
총함, 평균 등 하나의 결과로 나타난다.
* 집계 : 값을 확대,,? 하는,,
| 구분 | 설명 |
| SUM | 그룹의 누적 합계를 반환한다. |
| AVG | 그룹의 평균을 반환한다. |
| COUNT | 그룹의 총 개수를 반환한다. |
| MAX | 그룹의 최대값을 반환한다. |
| MIN | 그룹의 최소값을 반환한다. |
| STDDEV | 그룹의 표준편차를 반환한다. |
| VARIANCE | 그룹의 분산을 반환한다. |
[ 그룹 함수의 종류 ]
1. 합계를 구하는 SUM 함수
- SUM 함수
: 해당 컬럼 값들에 대한 총합을 구하는 함수
- 그룹 함수는 다른 연산자와는 달리 해당 컬럼 값이 NULL인 것을
제외하고 계산한다.
SELECT SUM(SAL)
FROM EMP;
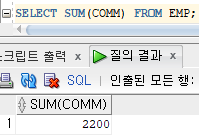
SELECT SUM(COMM)
FROM EMP; -- 그룹 함수와 NULL
-- 아래는 쉅 내용 코드 ---
--6-1-1. SUM 함수 : 합계 구하기
SELECT SUM(SAL) FROM EMP;
SELECT SUM(COMM) FROM EMP; -- SUM 함수는 NULL을 제외하고 합계한다.
2. 평균 구하는 AVG 함수
- AVG 함수
: 해당 컬럼 값들에 대해 평균을 구하는 함수
- 해당 컬럼 값이 NULL 인 것에 대해서는 제외하고 계산한다.
SELECT AVG(SAL)
FROM EMP;
-- 아래는 쉅 내용 코드 --
--6-1-2. AVG 함수 : 평균 구하기
SELECT AVG(SAL) FROM EMP;
SELECT AVG(COMM) FROM EMP; -- AVG 함수는 NULL을 제외하고 계산한다.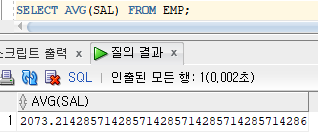

3. 최대값 구하는 MAX, 최소값 구하는 MIN 함수
- MAX 함수
: 지정한 컬럼 값들 중에서 최대값을 구하는 함수
- MIN 함수
: 지정한 컬럼 값들중에서 최소값을 구하는 함수
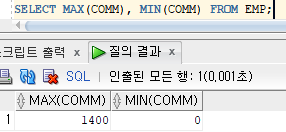
SELECT MAX(SAL), MIN(SAL)
FROM EMP;
-- 아래는 쉅 내용 코드 --
--6-1-3. MAX, MIN 함수 : 최대, 최소 구하기
SELECT MAX(SAL), MIN(SAL) FROM EMP;
SELECT SAL FROM EMP;
SELECT MAX(COMM), MIN(COMM) FROM EMP;

4. 그룹 함수와 단순 컬럼
- SELECT 문에 그룹 함수를 사용하는 경우,
그룹 함수를 적용하지 않은 단순 컬럼은 올 수 없다.
SELECT MAX(SAL)
FROM EMP;
SELECT ENAME, MAX(SAL)
FROM EMP; -- 오류 발생
-- 아래는 쉅 내용 코드 --
SELECT ENAME, MAX(SAL) FROM EMP;
-- ENAME의 값은 14개인데 MAX(SAL) 값은 하나라서 오류가 발생한다.
-- 오류) ORA-00937: not a single-group group function
-- 이와 같이 그룹 함수는 여러개의 값이 나오는 컬럼과 같이 사용할 수 없다



5. 로우 갯수 구하는 COUNT 함수
- COUNT 함수
: 테이블에서 조건을 만족하는 행의 개수를 반환하는 함수
SELECT COUNT(COMM)
FROM EMP;
SELECT COUNT(*), COUNT(COMM)
FROM EMP;
SELECT COUNT(JOB) 업무수
FROM EMP;
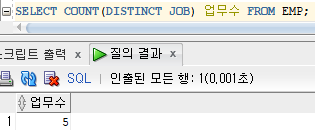
SELECT COUNT(DISTINCT JOB) 업무수
FROM EMP;
-- 아래 쉅 내용 코드 --
--6-1-4.COUNT : 로우(ROW) 개수 구하기, NULL의 개수는 제외하고 계산한다.
SELECT COUNT(*), COUNT(COMM) FROM EMP;
SELECT COUNT(JOB) 업무수 FROM EMP; -- 중복된 값 포함하여 개수가 계산된다.
SELECT COUNT(DISTINCT JOB) 업무수 FROM EMP; -- DISTINCT 해줘서 중복된 값 제외하고 개수가 계산되게 한다.

[ 2 ] GROUP BY절
- 그룹함수를 쓰되 어떤 컬럼 값을 기준으로 그룹함수를 적용할 경우
GROUP BY절 뒤에 해당 컬럼을 적으면 된다.
- 합계, 평균, 최대값, 최소값 등을 어떤 컬럼을 기준으로 그 컬럼의
값 별로 보고자 할 때 GROUP BY 절 뒤에 해당 컬럼을 적으면 된다.
- GROUP BY 절 사용할 때 주의할 점,
GROUP BY절 다음에는 컬럼의 별칭을 사용할 수 없고,
반드시 컬럼명을 적어 줘야한다.
* SELECT 절 : 컬럼
FROM 절 : 테이블
WHERE 절 : 조건
GROUP BY 절 : 그룹핑
ORDER BY 절 : 정렬
-- 형식
SELECT 컬럼명, 그룹함수
FROM 테이블명
WHERE 조건 (연산자) -- 생략 가능하다.
GROUP BY 컬럼명; -- 컬럼명을 지정하면 그 컬럼명으로 부르게 된다.
SELECT DEPTNO
FROM EMP
GROUP BY DEPTNO;
SELECT DEPTNO, AVG(SAL)
FROM EMP
GROUP BY DEPTNO;
SELECT DEPTNO, MAX(SAL), MIN(SAL)
FROM EMP
GROUP BY DEPTNO;
-- 아래 쉅 내용 코드 --
-- GROUP BY 절 : 그룹핑 --> 평균, 합계, 최대값 등을 구할 수 있다..
SELECT DEPTNO
FROM EMP;
SELECT DEPTNO
FROM EMP
GROUP BY DEPTNO;
SELECT DEPTNO, AVG(SAL)
FROM EMP
GROUP BY DEPTNO;
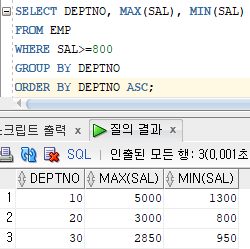
SELECT DEPTNO, MAX(SAL), MIN(SAL)
FROM EMP
WHERE SAL>=800
GROUP BY DEPTNO
ORDER BY DEPTNO ASC;



[ 3 ] HAVING 조건
- SELECT 절에 조건을 사용하여 결과를 제한할 때는 WHERE 절을 사용하지만,
그룹의 결과를 제한할 때는 HAVING 절을 사용한다.
* GROUP BY 절에 조건을 줄 때 HAVING 절을 사용해서 그룹에 대한 조건을 준다.
* SELECT 절 : 컬럼
FROM 절 : 테이블
WHERE 절 : 조건
GROUP BY 절 : 그룹핑
HAVING 절 : 그룹핑에 대한 조건
ORDER BY 절 : 정렬
---- 코드 적는 순서 (순서 바꿔서 실행하려고 하면 오류남,,)---
SELECT DEPTNO, AVG(SAL)
FROM EMP
GROUP BY DEPTNO
HAVING AVG(SAL) >= 2000;
SELECT DEPTNO, MAX(SAL), MIN(SAL)
FROM EMP
GROUP BY DEPTNO
HAVING MAX(SAL) > 2900;
-- 오늘 쉅 내용 코드 --
-- HAVING 절 : GROUP 의 조건을 준다.
SELECT DEPTNO, AVG(SAL)
FROM EMP
WHERE SAL>=800
GROUP BY DEPTNO;
SELECT DEPTNO, AVG(SAL)
FROM EMP
WHERE SAL>=800 -- FROM에 대한 조건
GROUP BY DEPTNO
HAVING AVG(SAL) >= 2000 -- 전체 그룹핑한 것에 대해 조건을 준것이다..?
ORDER BY DEPTNO ASC;
-- WHERE, HAVING, ORDER BY 절들은 생략 가능하다.

[ 4 ] 집합 연산자
1. UNION
- 집합의 합집합 개념
- 두 개 이상의 개별 SELECT 쿼리를 연결한다.
- 개별 SELECT 쿼리 반환 결과가 중복 되는 경우에
UNION 연산 결과는 한 로우만 반환된다.
-- 집합 연산자
DROP TABLE EXP_GOODS_ASIA;
CREATE TABLE EXP_GOODS_ASIA (
COUNTRY VARCHAR2(10),
SEQ NUMBER,
GOODS VARCHAR2(80));
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 1, '원유제외 석유류');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 2, '자동차');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 3, '전자집적회로');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 4, '선박');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 5, 'LCD');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 6, '자동차부품');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 7, '휴대전화');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 8, '환식탄화수소');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 9, '무선송신기 디스플레이 부속품');
INSERT INTO EXP_GOODS_ASIA VALUES ('한국', 10, '철 또는 비합금강');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 1, '자동차');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 2, '자동차부품');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 3, '전자집적회로');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 4, '선박');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 5, '반도체웨이퍼');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 6, '화물차');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 7, '원유제외 석유류');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 8, '건설기계');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 9, '다이오드, 트랜지스터');
INSERT INTO EXP_GOODS_ASIA VALUES ('일본', 10, '기계류');
COMMIT;
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
ORDER BY SEQ;
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본'
ORDER BY SEQ;
-- UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';



2. UNION ALL
- UNION 과 유사하다.
- 개별 SELECT 쿼리 반환 결과가 중복되는 경우,
중복되는 건까지 모두 반환한다.
-- UNION ALL
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
UNION ALL
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';

3. INTERSECT
- 집합의 교집합 개념
- 두 개 이상의 개별 SELECT 쿼리를 연결한다.
- 개별 SELECT 쿼리 반환 결과 중 공통된 항목만 추출한다.
-- INTERSECT
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
INTERSECT
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';

4. MINUS
- 집합의 차집합 개념
- 두 개 이상의 개별 SELECT 쿼리를 연결
- 개별 SELECT 쿼리 반환 결과 중 중복된 건을 제외한
선행 쿼리 결과를 추출한다.
-- MINUS
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
MINUS
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';
-- 위의 결과와 다르게 나온다 --
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본'
MINUS
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국';


5. 집합 연산자 제한사항 ( 그냥 슈웅- 넘어가심,,)
- 개별 SELECT 쿼리의 SELECT 리스트 개수와 데이터 타입이
일치해야한다.
- ORDER BY 절은 맨 마지막 개별 SELECT 쿼리에만 명시가 가능하다.
- BLOB, CLOB, BFILE 타입의 컬럼에 대해서는 집합 연산자를 사용할 수 없다.
- UNION, INTERSECT, MINUS 연산자는 LONG형 컬럼에는 사용할 수 없다.
-- 집합 연산자 제한사항
--1. 집합 연산자로 연결되는 각 SELECT문의 SELECT 리스트의 개수와 데이터 타입은 일치해야 한다.
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
UNION
SELECT SEQ, GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';
--ORA-01789: 질의 블록은 부정확한 수의 결과 열을 가지고 있습니다.
--01789. 00000 - "query block has incorrect number of result columns"
SELECT SEQ
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';
--ORA-01790: 대응하는 식과 같은 데이터 유형이어야 합니다
--01790. 00000 - "expression must have same datatype as corresponding expression"
--2. 집합 연산자로 SELECT 문을 연결할 때 ORDER BY절은 맨 마지막 문장에서만 사용할 수 있다.
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
ORDER BY GOODS
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본';
--ORA-00933: SQL 명령어가 올바르게 종료되지 않았습니다
--00933. 00000 - "SQL command not properly ended"
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '한국'
UNION
SELECT GOODS
FROM EXP_GOODS_ASIA
WHERE COUNTRY = '일본'
ORDER BY GOODS;
* 6장 과제는 SKIP! *
'DataBase' 카테고리의 다른 글
| 08_서브 쿼리 (0) | 2022.12.14 |
|---|---|
| 07_조인 (0) | 2022.12.14 |
| 05_SQL 주요 함수 (0) | 2022.12.13 |
| 04_SELECT로 특정 데이터 추출하기 (0) | 2022.12.13 |
| 03_SQL*Plus 명령어 (1) | 2022.12.13 |